TAO Real-Time Architecture
This page describes and compares the two main ORB designs we considered for
supporting Real-Time CORBA 1.0 in TAO. The first design, codenamed reactor-per-lane
and shown in Figure 1, was chosen for our initial implementation. The
second design, queue-per-lane, might also get implemented in the future,
as a part of a project evaluating alternative ORB architectures for Real-Time
CORBA.
Design I: Reactor-per-Lane
In this design, each Threadpool Lane has its own reactor, acceptor, connector
and connection cache. Both I/O and application-level processing for a
request happen in the same threadpool thread: there are no context switches, and
the ORB does not create any internal threads. Objects registered with any
Real-Time POA that does not have the ThreadpoolPolicy are serviced by default
threadpool, which is a set of of all the application threads that invoked
orb->run ().
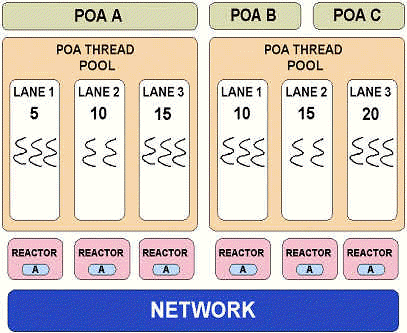
Figure 1: Reactor-per-lane
When a Real-Time POA is creating an IOR, it includes one or more of its
threadpool's acceptor endpoints into that IOR according to the following
rules. If the POA's priority model is server declared, we use the
acceptor from the lane whose priority is equal to the priority of the target
object. If the
priority model is client propagated, all endpoints from the POA's
threadpool are included into the IOR. Finally, if the PriorityBandedConnectionPolicy
is set, then endpoints from the threadpool lanes with priorities falling into one of the specified
priority bands are selected. The endpoints, selected according to the
rules above, and their corresponding priorities are stored in IORs using a special
TaggedComponent TAO_TAG_ENDPOINTS. During each
invocation, to obtain a connection to the server, the client-side ORB selects
one of these endpoints based on the effective policies. For example, if the object has
client propagated priority
model, the ORB selects the endpoint whose priority is equal to the priority of the client thread making the
invocation. If on the client-side, during invocation, or on the
server-side, during IOR creation, an endpoint of the right priority is not available, it
means the system has not been configured properly, and the ORB throws an exception.
The design and rules described above ensure that when a threadpool with lanes is
used, client requests are processed by the thread of desired priority from very
beginning, and priority inversions are minimized.
Some applications need less rigid, more dynamic environment. They do
not have the advanced knowledge or cannot afford the cost of configuring all of the
resources ahead of time, and have a greater tolerance for priority
inversions. For such applications, threadpools without lanes are a way to go.
In TAO, threadpools without lanes have different semantics that their with-lanes
counterparts. Pools without lanes have a single acceptor endpoint used in
all IORs, and their threads change priorities on the fly, as necessary, to
service all types of requests.
Design II: Queue-per-Lane
In this design, each threadpool lane has its own request queue. There is a separate
I/O layer, which is shared by all lanes in all threadpools. The I/O layer has one
set of resources - reactor, connector, connection cache, and I/O thread(s) - for each priority
level used in the threadpools. I/O layer threads perform I/O processing
and demultiplexing, and threadpool threads are used for application-level request
processing.

Figure 2: Queue-per-lane
Global acceptor is listening for connections from clients. Once a
connection is established, it is moved to the appropriate reactor during the
first request, once its priority is known. Threads in each lane are blocked on
condition variable, waiting for requests to show up in their queue. I/O
threads read incoming requests, determine their target POA and its threadpool,
and deposit the requests into the right queue for processing.
Design Comparison
Reactor-per-lane advantages:
- Better performance
Unlike in queue-per-lane, since each request is serviced in one
thread, there are no context switches, and there are opportunities for stack and TSS optimizations.
- No priority inversions during connection establishment
In reactor-per-lane, threads accepting connections are the same
threads that will be servicing the requests coming in on those connections, i.e.,
priority of the accepting thread is equal to the priority of requests on the
connection. In queue-per-lane,
however, because of a global acceptor, there is no differentiation between
high priority and low priority clients until the first request.
- Control over all threads with standard threadpool API
In reactor-per-lane, the ORB does not create any threads of its
own, so application programmer has full control over the number and
properties of all the threads with the Real-Time CORBA Threadpool
APIs. Queue-per-lane, on the other hand, has I/O layer threads,
so either a proprietary API has to be added or application programmer will
not have full control over all the thread resources..
Queue-per-lane advantages:
- Better feature support and adaptability
Queue-per-lane supports ORB-level request buffering, while reactor-per-lane
can only provide buffering in the transport. With its two-layer
structure, queue-per-lane is a more decoupled design than reactor-per-lane,
making it easier to add new features or introduce changes
- Better scalability
Reactor, connector and connection cache are per-priority resources in
queue-per-lane, and per-lane in reactor-per-lane.
If a server is configured with many threadpools that have similar lane
priorities, queue-per-lane might require significantly fewer of the
above-mentioned resources. It also uses fewer acceptors, and its IORs
are a bit smaller.
- Easier piece-by-piece integration into the ORB
Ease of implementation and integration are important practical
considerations in any project. Because of its two-layer structure, queue-per-lane
is an easier design to implement, integrate and test piece-by-piece.