|
|

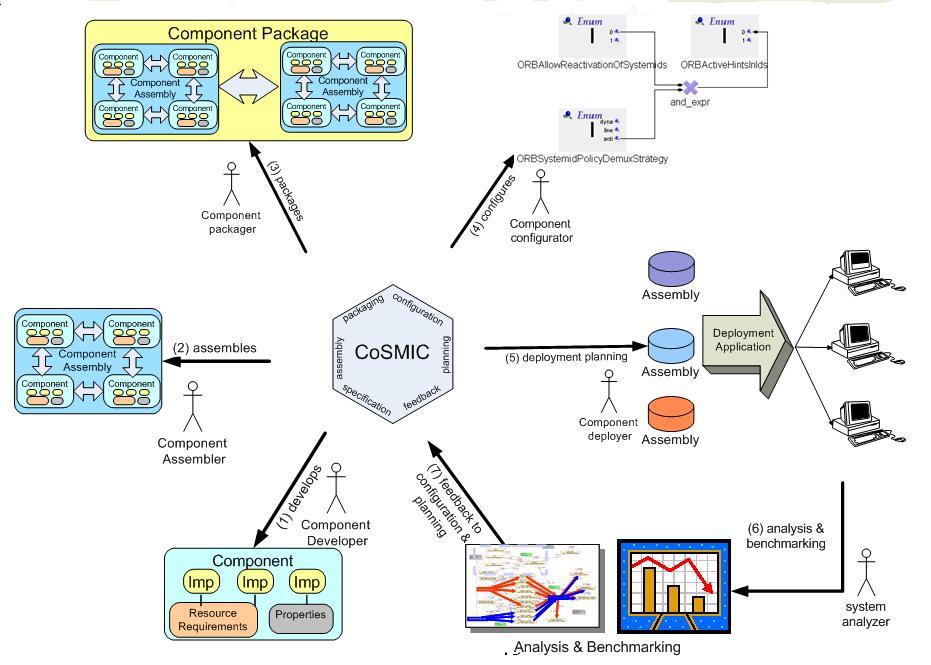
|
|
Operation Reference points to a two way IDL operation. BGML requires the signature of the operation to generate benchmarking code |
|
|
Event Reference points to a CORBA event exchanged between one/many components. The type of event is used by BGML to generate benchmarking code. |
|
|
Latency element is associated with an IDL operation/event. A latency element can be associated with only one operation or an event. The BGML model interpreter then uses this association to generate code the measures the latency for each invocation of the operation/event. For each latency element, attributes, e.g. file to send the output to, number of iterations, number of warmup iterations, rate and priority of the benchmarking tasks can be specified. |
|
|
Throughput element similar to
Latency is associated with an IDL operation/event. Every throughput element
can be associated with one operation or event. Similar to the latency
measures, the benchmarking code generates the throughput measures. The same
three attributes associated with Latency can also be associated with throughput |
|
|
Benchmarking experiments
require some background load either CPU or other requests during the
benchmarking process. These make the results more insightful. A TaskSet is a
set of tasks that can be used to create a certain number of background tasks
during the benchmarking experiment. |
|
|
A task represents a background
activity, in our case generation of requests during the benchmarking
process. These requests are remote CORBA operations on the target server
process. The number of iterations are the same as the benchmarking
operation. Each task set can be associated with n (1..n) number of background tasks. |
|
|
Time probe element can be used to generate timing information for both IDL operations and CORBA events. The start_time_probe () and stop_time_probe () functions generated from the BGML interpreters can be used to take timestamps before and after method invocation. These timestamps can then server as input to other timing analysis tools. Every timeprobe element can be associated with many operations and events. |




Workflow
The figure illustrates the BGML Workflow at a higher level for the creation of benchmarking experiments. As shown in the figure, these can be decomposed into four related steps. These are explained in the table next to the figure.
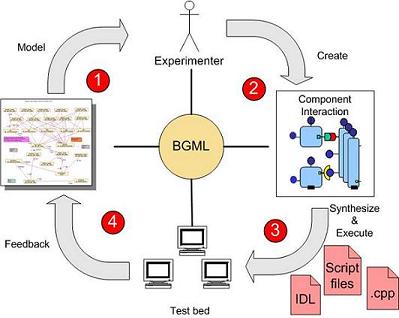
1. In the first step, the application scenario is visually depicted via PICML. This step also involves representation of the deployment plan.
2. Using BGML, an experimenter associates QoS properties, such as latency, jitter, or throughput with this scenario.
3. Using the model interpreters, synthesize the appropriate test code to run the experiment & measure the QoS.
4. Feedback metrics into models to verify if system meets appropriate QoS.
A detailed description of how one can use BGML is available in the BGML documentation guide which can be downloaded here. Additionally, one can install CoSMIC to play with examples available in the distribution to learn more about BGML.
Publications:
Arvind S. Krishna, Emre Turkay, Aniruddha Gokhale, and Douglas C. Schmidt,Model-Driven Techniques for Evaluating the QoS of Middleware Configurations for DRE Systems, Proceedings of the 11th IEEE Real-Time and Embedded Technology and Applications, San Francisco, CA March 2005.
Symposium, San Francisco, CA, March 2005.Middleware is increasingly being used to develop and deploy large-scale distributed real-time and embedded (DRE) systems in domains ranging from avionics to industrial process control and financial services. Applications in these DRE systems require various levels and types of quality of service (QoS) from the middleware, and often run on heterogeneous hardware, network, OS, and compiler platforms. To support a wide range of DRE systems with diverse QoS needs, middleware often provides many (i.e., 10's-100's) of options and configuration parameters that enable it to be customized and tuned for different use cases. Supporting this level of flexibility, however, can significantly complicate middleware and hence application QoS. This problem is exacerbated for developers of DRE systems, who must understand precisely how various configuration options affect system performance on their target platforms.
Arvind Krishna, Douglas C. Schmidt, Adam Porter, Atif Memon, Diego Sevilla-Ruiz, Improving the Quality of Performance-intensive Software via Model-integrated Distributed Continuous Quality Assurance, The 8th International Conference on Software Reuse, ACM/IEEE, Madrid, Spain, July 2004.
Quality assurance (QA) tasks, such as testing, profiling, and
performance evaluation, have historically been done in-house on
developer-generated workloads and regression suites. Performance-intensive
systems software, such as that found in the scientific computing grid and
distributed real-time and embedded (DRE) domains, increasingly run on
heterogeneous combinations of OS, compiler, and hardware platforms. Such
software has stringent quality of service (QoS) requirements and often provides
a variety of configuration options to optimize QoS. As a result, QA performed
solely in-house is inadequate since it is hard to manage software variability,
i.e., ensuring software quality on all supported target platforms across all
desired configuration options. This paper describes how the Skoll project is
addressing these issues by
developing advanced QA processes and tools that leverage the extensive computing
resources of user communities in a distributed, continuous
manner to improve key software quality attributes.
Contact Me |CoSMIC |Home Page | Institute for Software Integrated Systems